Designing for Resilience in Message-Driven Systems

Poison messages, DLXs, parking queues, retries, and global throttles — done right
TL;DR
Message queues break in sneaky ways — usually at 3AM, when a single malformed message blocks the rest of the pipeline.
To make your system resilient, you need:
- Dead-letter exchanges (DLX) to isolate poison messages
- Parking queues for manual triage and inspection
- Retry queues with exponential or Fibonacci backoff
- Throttle locks for system-wide rate limits
- A controlled flow to combine all of it
This post walks through the design, the implementation, and the tradeoffs of each.
TOC
- TL;DR
- Blocked Queues & Poison Messages
- Parking Queues
- Retry Queues
- Combine Retry Queues & Parking Queues
- Global Throttling (Temp Locks)
- Conclusion and Takeaways
Blocked Queues & Poison Messages

Here, the 2 green payload will be processed
However the red one contains a message that cannot be processed. So the message is nack, and stay on top of the queue.
All subsequent blue messages will never be processed.
One malformed or logic-failing message causes the consumer to crash or retry endlessly.
If you're using a queue with in-order delivery (like RabbitMQ, SQS FIFO), the rest of the messages never get processed. This is the poison message problem.
What counts as poison?
- Invalid JSON or schema
- Missing required fields
- Downstream failure (e.g., external API 500)
- Business logic failure (e.g., duplicate invoice)
Parking Queues
If a message fails, instead of letting it on top of the queue, push the poison message to a parking queue where your Tech / Ops team will review the message manually

Here, all valid payloads will be processed by the consumer,
If the consumer encounters an invalid payload and nacks it, it will be sent to the parking queue.
There it can be safely consumed and processed manually without blocking the remaining payloads
✅ Use a Dead-Letter Exchange (DLX)
In RabbitMQ (or any AMQP system), a DLX lets you route failed messages to a separate queue — so they don’t clog the main one.
Example Config:
{
"x-dead-letter-exchange": "parking.exchange",
"x-dead-letter-routing-key": "poison.billing"
}When your consumer does:
channel.nack(msg, false, false);the message gets routed to the DLX — and lands in the parking queue.
🔪 Parking Queue = Quarantine
This queue is:
- Monitored
- Searchable
- Replayable
- Attached to alerting
🟢 Pros:
- Poison messages don’t block the system
- You keep the data for debugging
- Clean triage interface
🔴 Cons:
- Breaks in-order guarantee
- Requires manual replay flow
- You need a UI/CLI to inspect the queue
Retry Queues
What if the failure was transient?
Like:
- Rate limit on Stripe
- DB lock timeout
- API flakiness
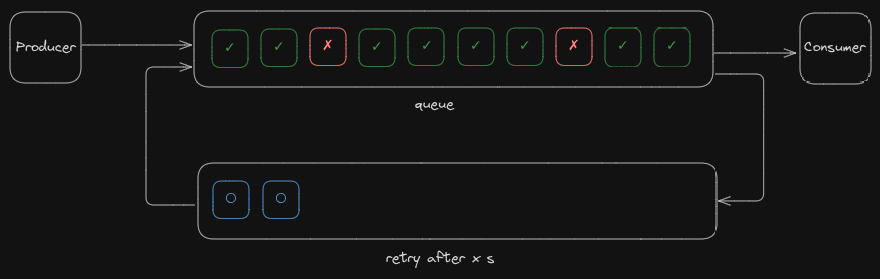
You don’t want to dead-letter right away. You want to retry after a delay.
✅ Use retry queues with TTL + DLX
| Queue Name | Delay TTL | DLX (on expiry) |
|---|---|---|
| retry_1s | 1000ms | main.exchange |
| retry_3s | 3000ms | main.exchange |
| retry_5s | 5000ms | main.exchange |
Each queue holds the failed message for a period, then auto-routes it back to the main queue.
{
"x-message-ttl": 3000,
"x-dead-letter-exchange": "main.exchange",
"x-dead-letter-routing-key": "billing.task"
}
🟢 Pros:
- Automatic recovery for flaky errors
- Minimal engineering overhead
- Safer than blind requeue
🔴 Cons:
- Requires multiple queues/exchanges
- State machine logic for tracking retry count
- Still breaks ordering
ℹ️ So far
# Main Queue
{
"x-dead-letter-exchange": "retry.3000",
"x-dead-letter-routing-key": null // empty to use the same
}
# Retry Queue
{
"x-message-ttl": 3000,
"x-dead-letter-exchange": "main.exchange"
}Combine Retry Queues & Parking Queues

You may have guessed but both parking queues and retries use dead letter exchange, and one queue cannot have two dead letter targets.
FYI: when you channel.nack(message, false, false), you actually tell rabbit that you killed the message and rabbit sets a x-death header with an array representing death reasons:
// x-death header after being nack by consumer and requeued by retry-queue
[
{
"count": 2,
"exchange": "retry.3000",
"queue": "retry_3000",
"reason": "expired"
},
{
"count": 2,
"exchange": "",
"queue": "",
"reason": "rejected"
}
]
Which means your consumer can chose to:
- retry a message \(n\) times...
- and push directly to the
parking queuewhen a message has been tried \(\text{count} > n\) times OR when a message just isn't worth retrying
If you want to implement a Fibonacci / Exponential retry system, that's also the way to go
Global Throttling (Temp Locks)
Sometimes the whole system is under load, and retrying just floods it more.
❌ Problem:
Retry queues with backoff retry each message individually, even during global rate limits.
✅ Solution: Use a Throttle Lock or Circuit Breaker
Option 1: Global Pacing Queue
- Funnel retries into a separate queue
- Drain it at a safe rate with a scheduler or worker
Option 2: Redis Flag
if (isRateLimited()) {
await redis.set("stripe:throttle", true, "EX", 30);
}
if (await redis.get("stripe:throttle")) {
channel.nack(msg, false, true); // requeue, no retry count increment
return;
}Option 3: Pause the Worker
worker.pause() ➜ sleep 30s ➜ worker.resume()🧠 Rule of Thumb
- Retry queues for message-level failures
- Throttle locks for system-level failures
The option you chose depends on how many workers process a single queue
Conclusion and Takeaways
Poison messages will happen.
APIs will fail.
Schemas will evolve.
You can’t prevent failure — but you can control how it flows.
✅ Resilience Patterns Recap:
| Pattern | When to Use | Tradeoffs |
|---|---|---|
| DLX + Parking Queue | For poison messages / malformed input | Breaks order, needs triage |
| Retry Queues | For transient, message-specific failure | Adds infra, may flood system |
| Global Throttle Lock | For rate-limits or shared resource issues | Needs coordination, queue-level |
| Combined Flow | All the above, in the right sequence | Highest resilience |
🚧 Production Checklist
- ☑️ Consumer is idempotent
- ☑️ Retries are capped
- ☑️ Retry delay increases with attempt count
- ☑️ Parking queue is monitored
- ☑️ All failures are logged with context
- ☑️ Replay CLI/UI exists
- ☑️ Throttle lock is respected
Code fails. Networks flake.
Design for it. Or suffer at scale.